Pretranlsation rules allow the system to insert TM matches and machine translation into the target text before the work even starts. This significantly speeds up the translation process.
Adding Pretranslation Rules
- Open the Pretranslation tab.
- Adjust the settings for numbers. If the source text contains a lot of numbers, click Source (Numbers Only) so that all the segments containing only numbers will be copied to the translation. Decimal and thousand separators, in this case, will be converted to match standards of the target language, at least in most cases. The rule for inserting numbers is always the first to execute.
- Click Add Rule → Translation Memories to enable automatic insertion of the translations from the existing translation memories and save on editing.
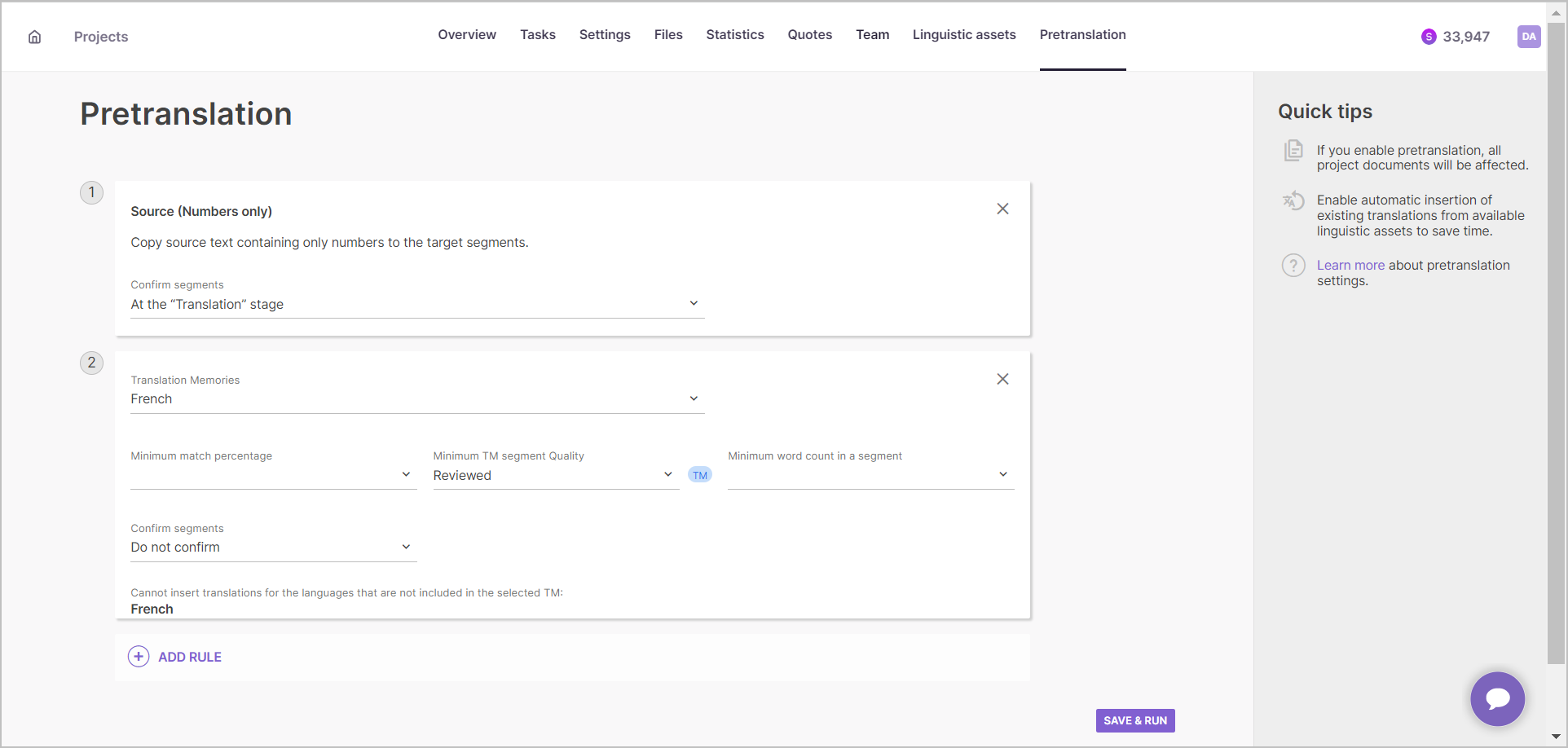
4. Select which TM you want to use from the ones you have enabled on the project. In the Minimum match percentage field, specify the minimum match percentage for a segment in the document and the translation memory at which the system must insert a translation from the TM.
You can also specify the Minimum segment count (in words) so the matches must be inserted based on the segment length. This can be useful to eliminate the risk of inserting an improper wording.
In the Minimum segment quality you can select to use only reviewed segments to avoid inserting unedited translation.
Finally, in the Confirm segments field specify if the system should confirm the inserted translations and at a specific stage.
5. Click Save&Run. The pretranslation rules will be applied to all existing and future documents within a project — so you don’t need to configure them for individual documents.
Pro tips
- If you are sure of the quality of the translations in the applied TM and have set the minimum match percentage at 100%, you can specify that the system must confirm at the translation stage for such matches and have the editor to review such segments.
- If you have doubts about the quality of the TM units or have set the match threshold below 100%, you should not specify automatic confirmation of such matches since there might be segments required reviewing on the first stage. In this case, matches will be inserted, but the translator will check them, making corrections if necessary, and then manually confirming them.
- In cases where you have context matches (101% and above), you could even confirm segments for all the stages of your workflow.
- You can set up separate rules for each TM in a project (if there is more than one). The rules are executed one after the other; therefore, you should set the most reliable translation memory first.
- You can set more than one rule for each TM: for example, you can have Smartcat first insert 100% matches and confirm them, and then insert matches that are 75% and up, but without confirmation.
Did this article help you find the answer you were looking for? If not or if you have further questions, please contact our support team.
