Smartcat offers different options to process files depending on the original format. Below are some explanations for these options.
Excel
Generally, processing files using CAT tools required the users to copy and paste content from file to file if only some rows or columns needed to be processed. Smartcat simplifies the process greatly and eliminates the need to prepare files in advance. If you click on an Excel file that was added in the first step of the project creation process, these options will be shown on the right side:
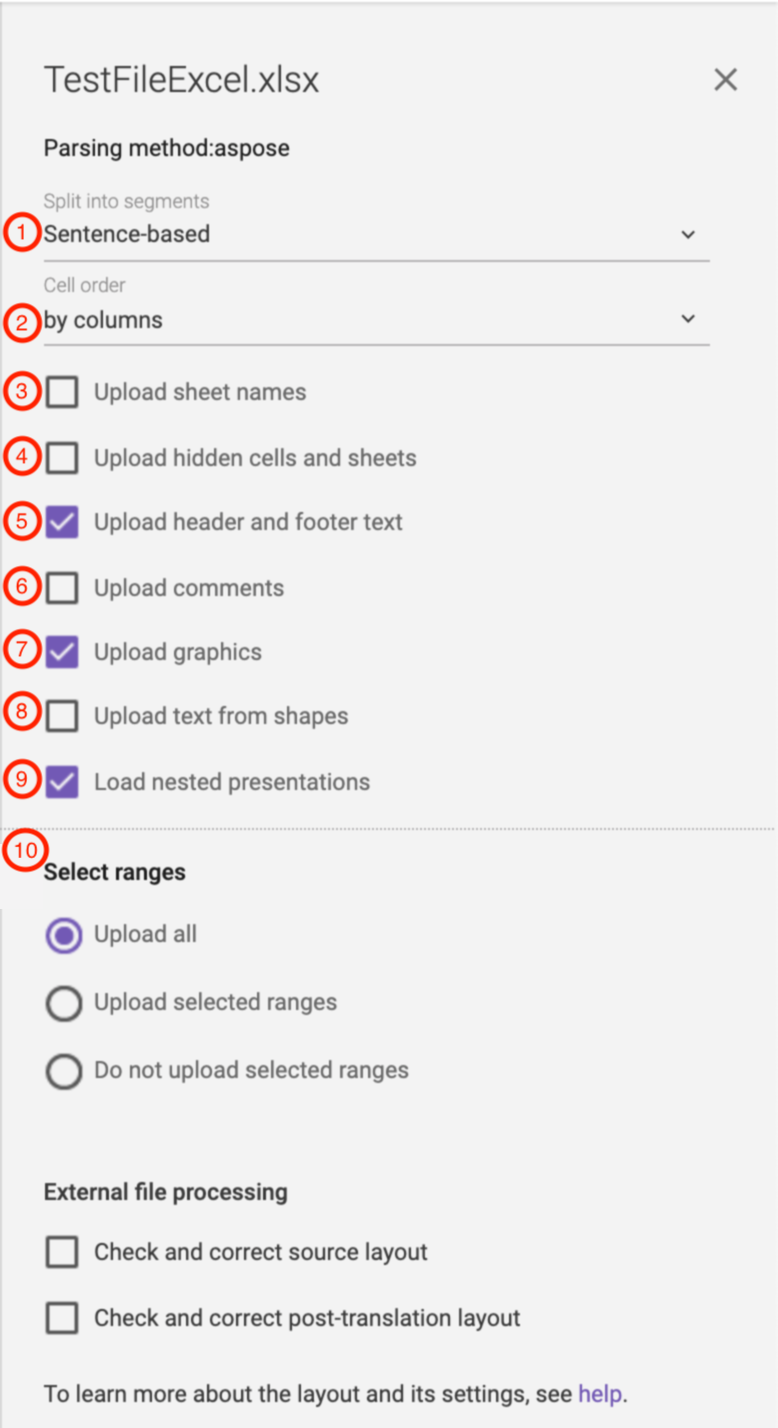
(1) You can choose to split segments based on Sentences or Cells.
If a cell contained the following content — Lorem ipsum. Dolor sit amet. And you were to choose the “Cell-based” option, you would end up with one segment in the editor:
Lorem ipsum. Dolor sit amet.
Whereas, if you chose the Sentence-based option, the content would be split into 2 segments:
- Lorem ipsum.
- Dolor sit amet.
It is generally better to segment by sentences as it is more helpful to your Translation Memory to have smaller segments because you will have fewer matches to entire paragraphs than you would with smaller sentence segments.
(2) This option will tell Smartcat whether to parse the excel spreadsheet horizontally (by rows) or vertically (by columns)
(3) Determines whether the sheet names are included in the document upload.
(4) Determines whether the hidden cells and sheets are included in the document upload.
(5) Determines whether the header and footer content is included in the document upload.
(6) Determines whether the comments are included in the document upload.
(7) Determines whether the graphics are included in the document upload.
(8) Determines whether the text from shapes is included in the document upload.
(9) Determines whether the text from nested presentations is included in the document upload.
(10) If you select either the “Upload selected ranges” or “Do not upload selected ranges” you are presented with the following options:

In this section, you can decide exactly which portions of an excel file are uploaded or not to the project. To select columns, enter the names of the first and last columns you need, for example, A:H. To select rows, enter the names of the first and last lines you need, for example, 1:50. Or you can use a combination of the two. For instance, if you wanted to translate a document that had columns A-Z and rows 1 through 100 but you wanted to omit column B you would apply the following rules:

If you had selected “Do not upload selected ranges” the only column that would be included in the upload of Sheet1 would be column B. You can also create rules for each of the sheets in your excel file:
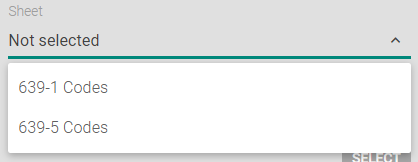
And you can apply separate rules for each sheet like so:

Here, in one sheet column, A would be processed and in the other, it would be column B. Smartcat gives you a lot of flexibility to deal with Excel files — no need to hide columns or copy and paste the content to be translated.
XLIFF
XLIFF is a standard file format used to exchange translation data between tools. They can be produced by Content Management Systems (CMS) or other CAT tools. It is convenient because the file can contain both source and target languages already segmented as well as some information regarding the status of the segments. There are many advanced file options for XLIFF documents when they are imported in Smartcat. Here is a basic overview:

(1) This option allows you to choose between keeping the segmentation of the document exactly as it is in the original document by selecting “Like the source file” or splitting existing untranslated segments into sentences by selecting “Additionally segment untranslated units”. This option can be useful if the document was segmented by paragraphs originally since you have better chances to find matches in the TM with single sentences. This will be done automatically during the processing of the file.
(2) This option refers back to the first option. If you selected the “Additionally segment untranslated units” option and split the original segments into sentences - the first option would revert the segmentation back to the segmentation of the original file when you export the file. If you select the “No, use Smartcat segmentation” option, the exported file would be segmented in the same way that Smartcat processed it and re-segmented the file. Typically, it is better to revert the file’s segmentation to the original segmentation because otherwise, it could cause problems when the file is reimported by the client.
(3) When you import an XLIFF file it may already have translations inserted. If you want to keep these translations, you would choose the “Yes” option. This would be particularly useful if you had translated the file with a different CAT tool and then wanted to assign an editor through Smartcat. If you were to select “No” the translated segments would be ignored and the translation would have to be restarted from scratch.
(4) If the file has pre-translated segments this option allows you to choose when the segments are confirmed inside of Smartcat. So for instance, if your project had TEP (Translation, Editing, Proofreading) workflow stages and you selected the option “Yes, at the last stage” the segments would be confirmed as having been Proofread and locked for the linguistic team. If you selected the option “Yes, at the first stage” the segments would be confirmed as having been translated but would still require Editing and Proofreading confirmation.
If you select the option “Yes, for segments with the status:” it will open a popup as shown below:
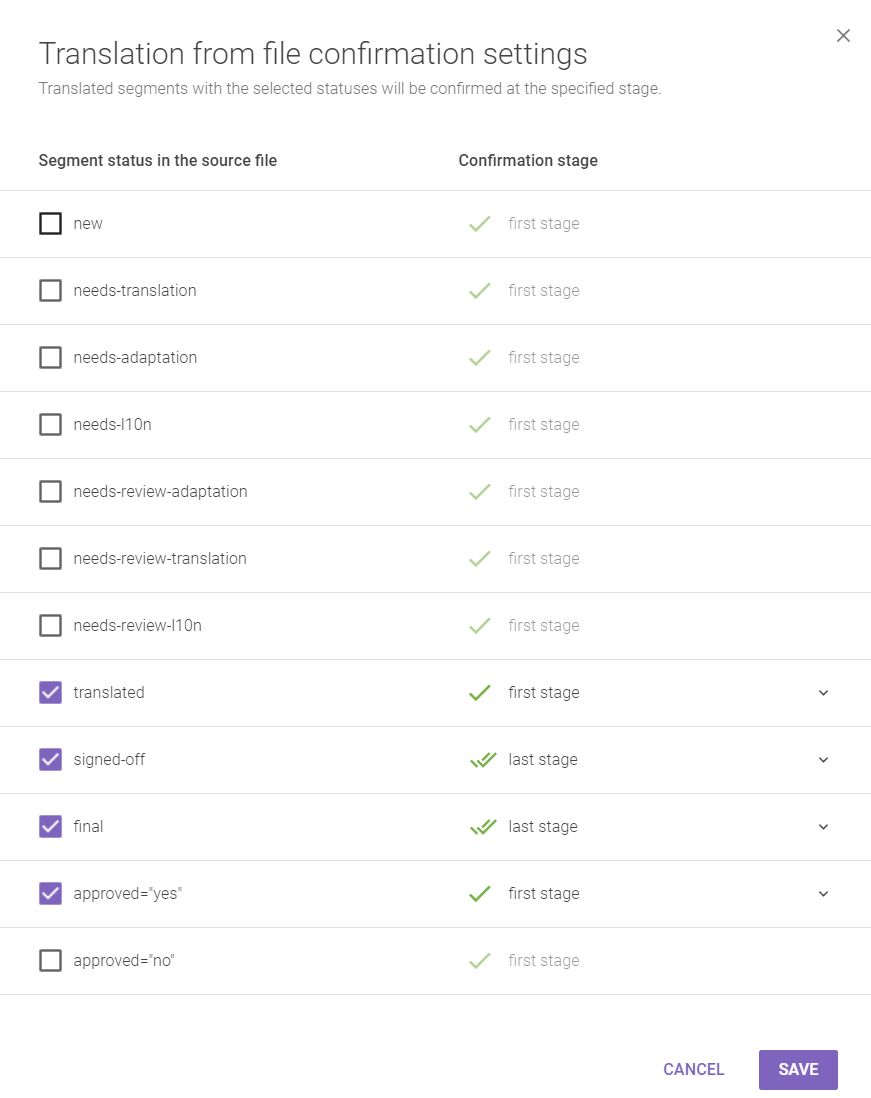
Here, you would be able to customize the confirmation of segments based upon their status as indicated in the XLIFF file and their workflow stage in Smartcat. For example, in the screenshot above, segments with the "final" status in the XLIFF file would be approved as Proofread in Smartcat. Segments with the status "translated" would be approved only for the translation stage.
(5) This option allows you to completely lock segments so that no further action can be taken. If you select the “Yes, with statuses:” option then a popup will open displaying the statuses shown in the previous picture. You will be able to select specific statuses and when Smartcat parses the document it will lock all the segments containing matching statuses as the ones you selected.
If you were to choose the “Yes, with translations inserted from file and confirmed” option then the segments which had been confirmed through (4) would also become locked.
(6) Although it is not common, checking this box off will allow the use of intersecting tags as shown in the help text:

(7) Placeholders are used to protect part of the text that should not be translated. See our article about placeholders for more information.
(8) This is not used when processing XLIFF files.
XML
There are several different types of XML file parsing methods that Smartcat handles besides the powerful flexible XML method:

The structure of files varies depending on the types of tags you expect to see in the file type. With XML you are free to create whatever tags you would like to create. This can cause difficulty in the parsing of the file so each of these parsing methods follows a standard of expected tags based on the XML type.
For instance, in a standard HTML document, you would expect to see <p> (Paragraph) tags but in a DITA XML file you can expect to find predefined tags in the DITA standard such as <xref> which is shown below:

By adhering to these standards the file can be parsed appropriately. For instance, in the example above the document might split segments when it hits the <xref> opening tag, but because the tag is recognized by the DITA standard, the segments are not inappropriately divided here.
If you choose DITA or standard XML you will see another dropdown with the following options:
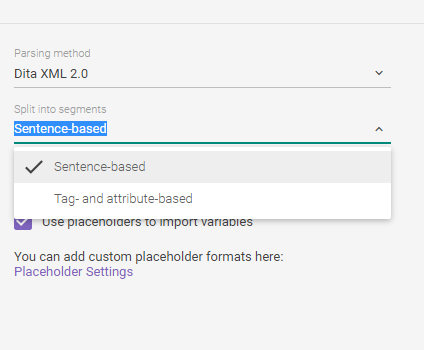
They allow a user to split segments either by sentences or by tags and attributes. For instance, you may have multiple sentences contained within a paragraph tag:
<p> Lorem ipsum. Dolor sit amet. </p>
If you choose Tag and attribute-based, you will end up with one segment:
Lorem ipsum. Dolor sit amet.
Whereas, if you chose Sentence-based, the text will be segmented as follows:
- Lorem ipsum.
- Dolor sit amet.
As with the other format, it is generally better to segment XML files by sentences as it is more helpful to your translation memory to have smaller segments. You will have fewer matches to entire paragraphs than you would with smaller sentence segments.

(1) Some Content Management Systems (CMS) will use CDATA sections and in these CDATA blocks, they will store sections of HTML code. If you select this option, Smartcat will first parse the entire document and then go through the CDATA blocks and parse those sections again to look for HTML tags to protect them.
(2) By using placeholders (see our Placeholder article), you can import and protect variables contained in XML files.
When you add PDF files (or any graphic files) to a project, the files are first processed using Optical Character Recognition (OCR) to extract the text to be translated as well as maintain the format whenever possible. There are very few Advanced File Options for a PDF file like using OCR or not and checking the source layout.

Please note that the file should not exceed 30 MB in size to be recognized. If your PDF is too large, consider splitting it into smaller parts, and upload as separate PDF files to avoid error.
PowerPoint
The PowerPoint advanced file options can be seen here:
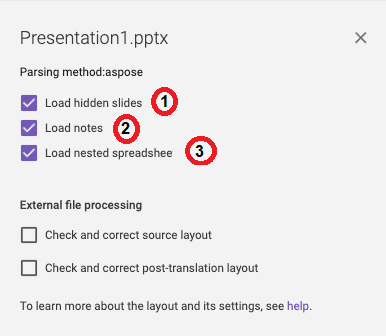
These options are fairly straightforward.
(1) allows you to upload slides even if they are hidden.
(2) allows you to upload the notes section of each slide.
(3) allows you to upload spreadsheets that have been inserted into the PowerPoint presentation.
Word (DOCX)
There are only two unique options for Word files as shown below:
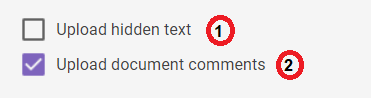
(1) allows you to upload text from a Word file even if it is hidden.
(2) allows you to upload the comments from a Word file.
Did this article help you find the answer you were looking for? If not or if you have further questions, please contact our support team.
